BigData
Apache Flink 훑어보기
맥모닝프로
2025. 4. 3. 16:57
소개
- 대규모 스트리밍 분산 처리 프레임 워크
- 배치 처리도 스트리밍처럼 처리 가능
- 상태 기반 처리
Flink 데이터 파이프 라인 예시

- 이벤트 기반 애플리케이션
- 하나 이상의 이벤트 스트림에서 이벤트를 수집
- 계산, 상태 업데이트 또는 외부 작업을 실행
- 상태 저장 처리를 통해 수집된 이벤트 기록에 따라 단일 메시지 변환 이상의 논리를 구현 가능
- 데이터 분석 애플리케이션
- 데이터에서 정보와 인사이트를 추출
- 지속적인 업데이트, 쿼리 스트리밍 또는 수집된 이벤트를 실시간으로 처리
- 결과를 지속적으로 내보내고 업데이트하여 분석
- 데이터 파이프라인 애플리케이션
- 한 데이터 스토리지에서 다른 데이터 스토리지로 이동할 데이터를 변환 및 강화
- 프로세스가 지속적으로 작동하여 짧은 대기 시간으로 데이터를 다른 대상으로 이동 가능
Flink의 이점
| 구분 | 내용 | 비고 |
| 무제한(스트림) 및 제한된(배치) 데이터 세트 모두 처리 |
|
|
| 대규모로 애플리케이션 실행 |
|
|
| 인 메모리 성능 |
|
|
| 정확히 한 번 상태 일관성 |
|
|
| 다양한 커넥터 |
|
Flink HA 동작 방식
- Task별로 StateBackend + Checkpoint 구조로 저장
- 중간 저장 데이터 없이 checkpoint만으로 Task 복구
HA 핵심 구성 요소
구성요소역할비고
| 구성 요소 | 역할 | 비고 |
| JobManager (여러 개) | 작업 스케줄링과 상태 관리 |
|
| TaskManager | 데이터 처리 실행 (실제 연산 담당) | |
| Zookeeper |
|
|
| State Backend | 상태 저장 (RocksDB, Memory, FileSystem 등) |
장애별 처리 흐름
| 장애 구분 | HA 동작 | 비고 |
| JobManger 다운 |
|
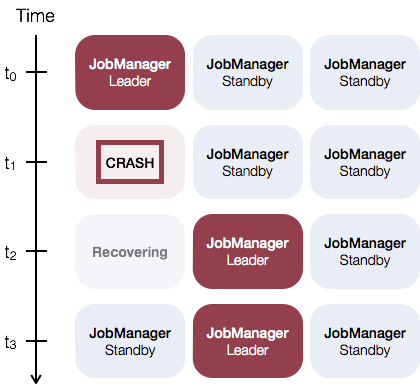 |
| TaskManager 다운 |
|
|
참고자료
- Apache Flink: https://flink.apache.org/
- Apache Flink HA: https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/ha/overview/
- AWS Apache Flink: https://aws.amazon.com/ko/what-is/apache-flink/
Apache Flink® — Stateful Computations over Data Streams
flink.apache.org